Embeddings and RAG
Retrieval Augmented Generation is a rather complicated way of saying “fetching extra data to add to a request”.
In order to fetch the data we need we use a concept called embeddings.
Simply, embeddings are just a way of representing words as numbers. These numbers can then be used to find similar other words very easily. So given a text query we can very quickly look up information that is similar in context to it.
I find it easier to refer to just “embeddings” as your AI’s memory, and performing RAG is just fetching information from the memory to use as context.
Here’s OpenAI’s official definition:
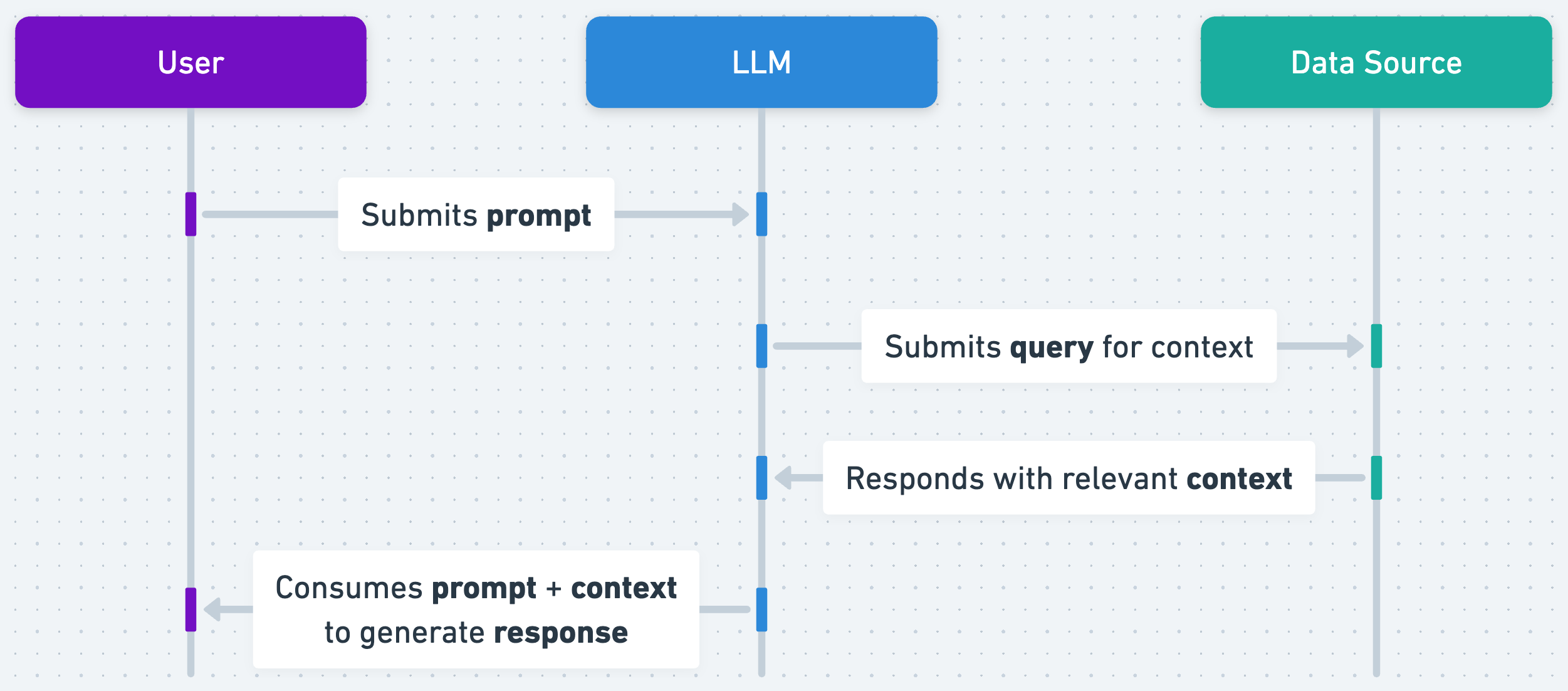 Pinecone would be the Data Source in StartKit.AI
Pinecone would be the Data Source in StartKit.AI
How this works in StartKit.AI
StartKit.AI performs the difficult (or boring) parts of RAG for you.
Using the Embeddings API you can upload any kind of text, certain types of documents, or provide URLs for the text to be fetched from.
The text is normalized and split into chunks and inserted it into Pinecone. This usually takes a few seconds, and returns a contextId.
You can then use this context ID when making any Chat request (or multiple context IDs). Pinecone will be automatically searched for any text chunk that matches the request sufficiently, and that will be added as context to the request.
Embeddings with the Chat API
The Chat APIs will automatically search Pinecone if a context ID is provided. This takes place via AI function calling, so it is actually the AI that decides if it requires additional data.
This has a significant benefit over making the request manually, as with function calling the AI understands that the data has come from a vector database, and can make it’s own determination on how relevant it is.
Results aren’t very good?
If you’re not getting the results that you want then you can manually make the request for embeddings and append it to your query.
I usually do something like this:
// exmaple system prompt, make sure to specify there's going to be extra contextconst systemPrompt = `You answer questions about documents, if there is context for the request then it will be provided under "Context" headers.`;let userPrompt = ['What is a subspace field?'];
const contexts = await queryEmbeddings({ query: userPrompt, top: 3, contextIds: ['1710012052356-10430406-warp.pdf'], namespaces: [userUuid, 'global'] // always provide the user uuid as a namespace});
for (let context of contexts) { userPrompt.push(`# Context`, context.text);}
let messages = [ { role: 'system', content: systemPrompt }, { role: 'user', content: userPrompt.join('\n') }];// next: do the chat requestHowever, in our experience you’ll get much better results using our function calling method.
The retrieval plugin
Behind the scenes StartKit.AI uses an open-source library built by OpenAI called their chatgpt-retrieval-plugin. This is what ChatGPT uses itself for fetching and storing it’s memory.
You should have access to our fork of the project here.
Our fork is functionally the same, but with extra bits added for usage monitoring and support for the latest version of Pinecone.
The chatgpt-retrieval-plugin is included in StartKit.AI as a submodule and started when you run the app. It depends on python and poetry to run, which will be downloaded when you install StartKit.AI using the create script.
If you don’t want to run the plugin when StartKit.AI runs then use the env variable NO_RETRIEVAL_PLUGIN. This allows you to run the server separately for a production deployment if you want.
Chat with us in the Telegram group if you want more info about this!
FAQ
The Chat endpoint isn’t using the correct data from it’s memory
This can happen. It’s possible that there isn’t a match in the memory that is close enough for the AI to think it’s relevant.
Also make sure that you’re using the correct Context ID when making your request or nothing will be found.
Can I use a different Data Source than Pinecone?
Pinecone is the data source we’ve decided to use by default because it’s very fast, very easy to use, and has a generous free tier. All you need to do is give StartKit.AI an API key and we can get started immediately.
However, there are a bunch more data sources available to use with the chatgpt-retrieval-plugin. If you have a request then let us know in the Telegram Insiders Group and we’ll try and help.
Is embeddings data private per user?
Yes, the data StartKit.AI stores in Pinecone is separated on a per-user basis by namespaces. So users of your app will only be able to access their own embedded data.